How do Netflix recommendations work?

About a decade ago, the idea of movies on demand for most of us was simply visiting a local store and renting a few DVDs, hoping to get our hands on the latest blockbuster flick of the week. For a decent subscription fee, this made monetary sense as the movie would take too long to release on cable television and not everyone was up for shelling out the time and money to watch it at the cinema. This business model worked well for Blockbuster, an American-based rental service, that at its peak was worth over $5 billion dollars. But only a decade later, it filed for bankruptcy, and spent the next couple of years shutting down all its stores (except one) and laying off thousands of employees across the state. It was pretty evident that the reason behind the downfall was the rise of online streaming platforms — a market share majorly dominated by Netflix to this day — that spearheaded the Kodak effect of modern innovation for Blockbuster.
Among the many advantages that an online streaming platform such as Netflix offers, is the service of personalisation. This is done by learning certain characteristic habits of the user and running it through a system to predict and curate a list of movies and shows that they may like. Such a system is aptly called a recommender system and is often used in e-commerce websites and music streaming services.
Netflix employs a very complex and proprietary recommendation engine to do the job by continuously learning from the user and improving its accuracy. The data used to make these predictions are collected from the users interaction on the platform, such as the most frequented genre, cast and production house. It also tracks which devices you use, how long you stream for and at what time of the day you are most likely to watch. All of these key data points act as a source of reliable feedback for the engine to improve the prediction accuracy.
Before we can understand this process in more detail, let’s take a look at a common problem faced in recommender systems.
The Cold Start Problem
Quite similar to an internal combustion engine after a long cold night, a recommendation engine must overcome what is commonly known as the ‘cold start problem’. When the user signs up and begins to interact with the service for the very first time, it has very little data about the user to suggest items that they may like. Netflix overcomes this by asking you to select at least three movies or TV shows from its catalogue that would serve as the initial data based off of which the recommendations are laid out. Once the user starts interacting with the service, the user data generated will begin to supersede the initial preferences and continue to drive the recommendation engine. Choosing out of the listings at the start is optional and skipping this will result in Netflix simply showing you a list of very popular movies and shows to get you started.
The Netflix Prize
In 2006, Netflix launched the Netflix prize, which was a data mining and machine learning competition with a prize money of $1 million dollars. The aim was to build a recommender system that would perform better than Cinematch — its proprietary recommender at the time — by over 10%. Cinematch had a Root Mean Square Error (RMSE) of 0.9525, and the team that beat this value, or came close to beating it would be awarded the prize money.
A year later, the KorBell team won the Progress Prize by using a linear blend of Restricted Boltzmann Machines (RBM) and Matrix Factorisation (a.k.a. SVD) to achieve a RMSE of 0.88, which was an improvement of 8.43%. To put this model to use, a few challenges were needed to be solved. For instance, the model was built to handle 100 million ratings, a far cry from the 5 billion ratings Netflix had at the time, and was incapable of handling new ratings from users. Once these issues were fixed in the source code, they were deployed, and are still a part of the production environment today.
The interesting thing is that the winners of the competition who won the grand prize two years later never had the chance to have their algorithm incorporated into the production recommender engine. Their work had showcased an impressive blend of algorithms and development work over the years that generated impressive accuracy values when tested offline. Which begs the question, why didn’t it make it into production? Well, there were two reasons. One, Netflix felt that the accuracy gain could not justify the immense effort needed to refactor the code so that it was suitable for production. The second reason was Netflix had changed its personalisation philosophy and moved from DVDs to streaming, that changed the way its recommendation engine worked and ingested data.
The Netflix Recommender System
Netflix utilises a dynamic grid layout where ranking is achieved using a two-tier row based ranking system. What this basically means is that given a single row, the strongest recommendation would be on the left. Also, each row is sorted with the highest recommendation appearing on top.
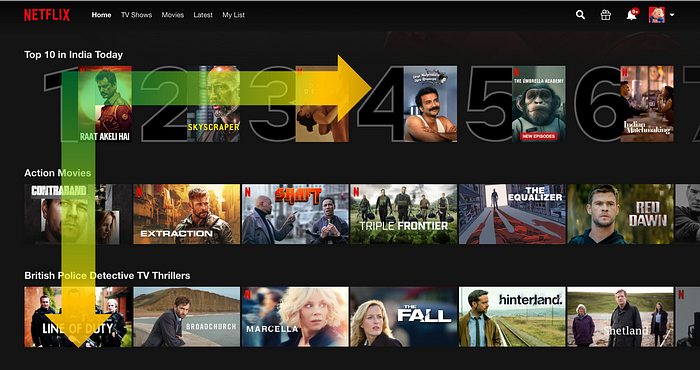
The intention behind this layout is two fold. For the user, it is much easier to decide what movie to watch in a given genre when it is sorted to our liking from left to right. For Netflix, they can track the interest of the user as they scroll across both axes. As they scroll towards the right for a given row, it indicates an interest in the genre but not necessarily in the ranking. Similarly as they scroll down, it indicates disinterest in the upper rows. Tracking this crucial data, the model realigns itself more towards the preference of the user and aims to push its highest recommendation towards the upper left hand corner.
An article by Netflix explains the various algorithms used to achieve its rank based recommendations. Let’s briefly take a look at some of them.
- Personalised Video Ranking (PVR) provides a general purpose relative ranking of the items within a row using the personalised data of the user. This is why for a given genre, two users may have a totally different ordered list. An example could be a row showing ‘Action Based Thrillers’.
- Top-N Video Ranker is similar to PVR except that it only looks at the head of the rankings and looks at the entire catalog. It is optimised using metrics that look at the head of the catalog rankings (e.g. MAP@K, NDCG). Rows such as ‘Top Picks for You’ are generated using this algorithm.
- Trending Now Ranker tries to predict temporal trends that may be strong predictions for a given time. The time period can range from a few days to a few months. There are typically two types of trends or events: 1. Events that are seasonal and tend to repeat themselves. For example, during Christmas, movies such Home Alone, The Polar Express and A Christmas Story may be recommended as people tend to prefer movies that highlight the holiday spirit. 2. One-off short term events. A good example is the current Corona virus pandemic that may lead to an uptick of pandemic related movies and documentaries.
- Continue Watching Ranker tracks the items that the user has watched, but not completed. This again can be further analysed under two categories: 1. Episodic content such as TV shows with multiple episodes and seasons. 2. Non-episodic content such as movies that may have been watched partially or independent episode TV shows such as Black Mirror.
- Video-Video Similarity a.k.a Because You Watched (BYW) is responsible for the ‘Because You Watched …’ row that we quite often see. The algorithm is quite similar to Content Based Filtering, in that it predicts based on an item consumed by the member and then computes other similar items (using an item-item similarity matrix) and returns the most similar items.
Up next is the Row Generation Process that involves a series of steps. This is the part where a set of rows are assembled for the user.
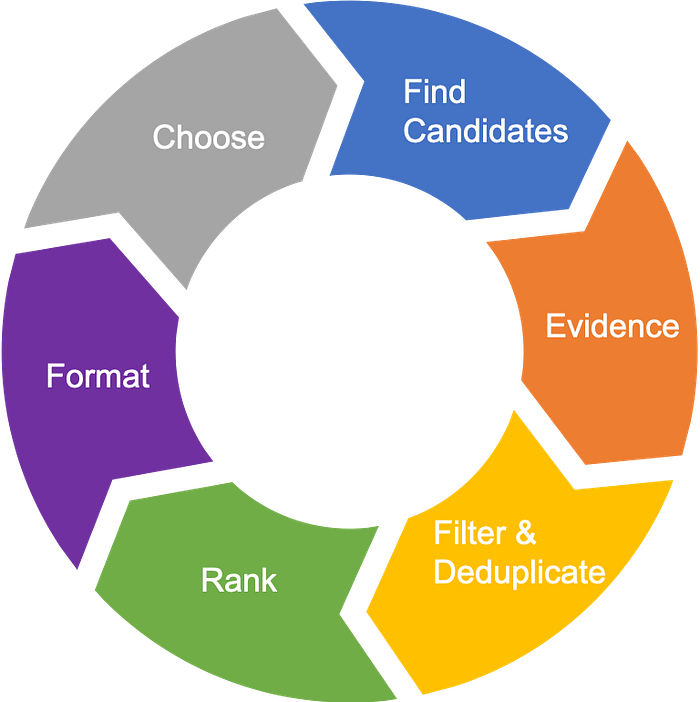
Candidate items are first chosen that are likely relevant for the user. This could involve having a large catalogue of items containing varying degrees of recommendations for the user. Evidence is then collected to view certain rows based on the user’s history. For instance, because they watched a lot of comedy TV shows in the past, a strong case can be made to push a row of other comedy TV shows to the top of the grid. The next step is to filter out possible concerns such as maturity ratings and country specific censor laws. Also deduplication takes place in this step to remove items already watched by the user. A row appropriate ranking algorithm is used to rank the items within each row such that the most relevant items appear at the beginning. From this set of row candidates we can then apply a row selection algorithm to assemble the full page.
This process will generate a large set of candidate rows which are already ranked within each row vector. The challenge now is to select a small subset of rows to display on the users page, which leads us to Page Generation.
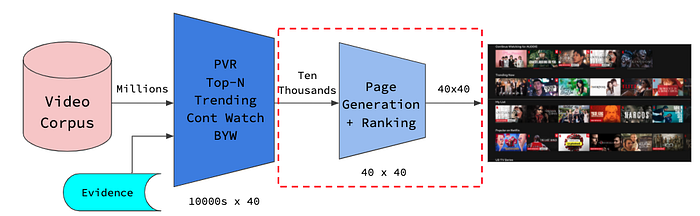
Netflix employees a template-based approach to tackle the problem of page generation. In other words, the rows are left to fight amongst each other for the precious screen real estate. This task not only focuses on accuracy (could be traced back to the change in Netflix’s philosophy in 2007), but also with diversity, accessibility and stability. What this means is that along with Netflix’s continued attempt to service the best possible recommendations to you, it’s also taking into consideration that you are still midseason of a TV show. At the same time, it is also trying to offer a fresh catalog of genres based on the recent trends. Another possible angle to consider is that humans are habitual creatures and are used to navigating the interface in a certain manner. These are some of the few vantage points that are considered during this process.
Although the template-based approach may seem as the optimum solution given the fixed set of criterions, it does not bode well in terms of user experience given the generation of a localised ideal case.
The solution is to use machine learning by creating a scoring function using a model that would train on historical page data that was created for their users. This includes what they actually see, how they interact with it and what they watch.
The idea is to use the features of the items in the best possible way and generate hypothetical pages only to observe the interaction of the user with them. For page-level quality, metrics very similar to what is used in information retrieval in one-dimensional lists is applied here, except now its two-dimensional. For instance, Precision@n — which measures the number of relevant items in the top n divided by the total number of relevant items — is now extended in two dimensions to be Recall@m-by-n where now we count the number of relevant items in the first m rows and n columns on the page divided by the total number of relevant items. One nice property of recall defined this way is that it automatically can handle corner-cases like duplicate videos or short rows. We can also hold one of the values n (or m) fixed and sweep across the other to calculate, for instance, how the recall increases in the viewport as the member would scroll down the page.
There are a lot of other components — from testing to deployment — in the system that enable this process and are outside the scope of this article. I shall list out a few sources below if you’re interested in learning about them. Hopefully this article gives you a fairly detailed idea of how the Netflix recommendation engine works.
So the next time you login to Netflix, take a moment to not only appreciate the computational marvel taking place behind the scenes, but also the arduous trip to the local movie-rental store that it is saving you from.
